All LaTex users know very well .bib files. These compact files allow writers worldwide to manage bibliographic references easily, reducing the burden of one of the most annoying aspects of being a scientist. But have you ever seen a .bib file containing more than 1500 references?
I got this when I automatically scraped all the 285 issues of the MathOnco Newsletter — almost seven years of effort condensed in a single bib file.
Starting today, you can access this file at the repository. We will keep that updated so you can download it for your bibliography or your following paper.
The way I could extract this impressive file is quite interesting. If you have always been interested in scientific scraping but need to know how to start, read the story below.
Step 0: How this started
I came in contact with the Mathematical Oncology blog a few months after the beginning of my Ph.D. at the Biocomputing UP Lab, University of Padova. My research focus is investigating the relationship between tumor growth and angiogenesis using deterministic models, so the website immediately intrigued me. I started following it, and after a few years, I can appreciate how crucial it was to stay updated on the most recent advancements in this fascinating field. Thus, I contacted Jeffrey West, this resource's creator and primary maintainer, to ask if I could contribute in any way. He kindly accepted my offer, and since then, I have been one of the editors of the weekly Newsletter we publish every week.
As I find it incredibly satisfying to automate repetitive tasks with Python, I created a tool to automatically query from PubMed and Google Scholar the most recent publications in Mathematical Oncology (LiRA: Literature Review Automated; blog post coming soon!). After a few months of contributions, Jeffrey asked me if I could help him do something he had always wanted to do: collect all the papers published in the MathOnco newsletter since 2017, when it started. So, I started working on it, and in the following, I will explain what I did.
Step 1: Getting the papers from the Newsletter
Like any other website, the newsletter is just an HTML file rendered by your browser. It is not hard to see the "true nature" of a Newsletter Issue using your browser's developer tools.
So, given the formatting in the newsletter, it is easy to programmatically navigate the page with Python to extract the content only from the "Papers" section. Fortunately, Jeffrey has kept the same format throughout the years (for the joy of all automation lovers), making the work pretty easy.
More precisely, I used Beautifoulsoup to manage the extracted HTML in Python. I noticed that the image starting the "Papers'' section and the image starting the following section ("Preprints") are simply two images with a unique identifier. So, I collected the text sections between these two identifiers and voilà! I could quickly get the papers in any issue of our beloved MathOnco Newsletter.
Figure 1: Simplified appearance of the “Publications” section in HTML.
Step 2: Using the title to retrieve the DOI
In the newsletter, we usually provide the link to every paper so our readers can easily read them. However, I needed the DOI to get the reference in any format (see the next section), and that's not easily derivable from the paper link. So, I spent some hours investigating the problem: is it possible to programmatically retrieve the DOI of a paper given its title?
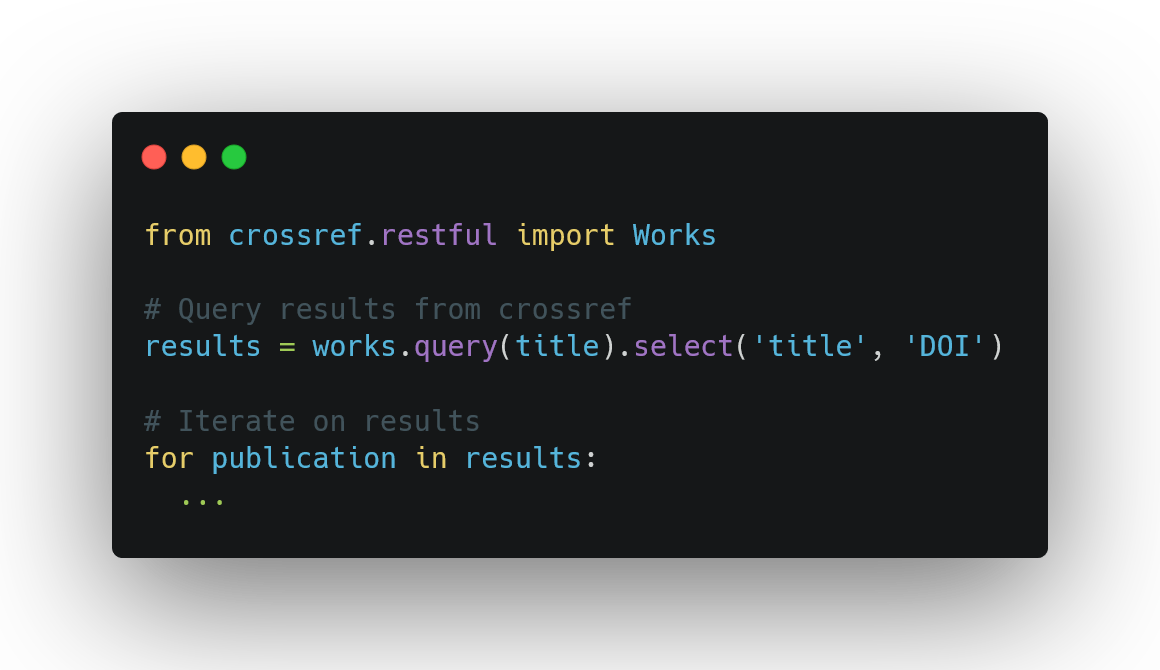
After a few hours online, I found a solution. CrossRef is an online resource to make research objects easy to find, cite, link, assess, and reuse. They have their own search engine for papers (and much more) and several free APIs to make queries on their database. If you go on their website and paste the title of any given paper, the search engine will return tons of results, but the first will often be the paper you're looking for. Doing the same with their API is very simple and will provide you with any information regarding that paper: the year, the authors, the journal, and the DOI.
Figure 2: Minimal example of usage of the CrossRef Python API (see more examples here).
Thus, thanks to CrossRef, I could retrieve the DOIs of the MathOnco publications, so having a unique identifier for each one.
The developer in me is not completely satisfied with this solution. The paper's title is not unique "by design," and the procedure at the beginning looked a bit naive to be consistent. However, after the first test, I noticed that I could retrieve the DOI of more than 90% of the MathOnco papers, so I had to leave my perfectionism on one side and admit that this solution was acceptable. Moreover, I also find this evidence kind of intriguing. We all put a lot of effort into making the titles of our papers catchy, original, and somehow unique. And the result we have is that the paper title is a strong identifier for a publication!
Step 3: Getting the Bib reference with the DOI
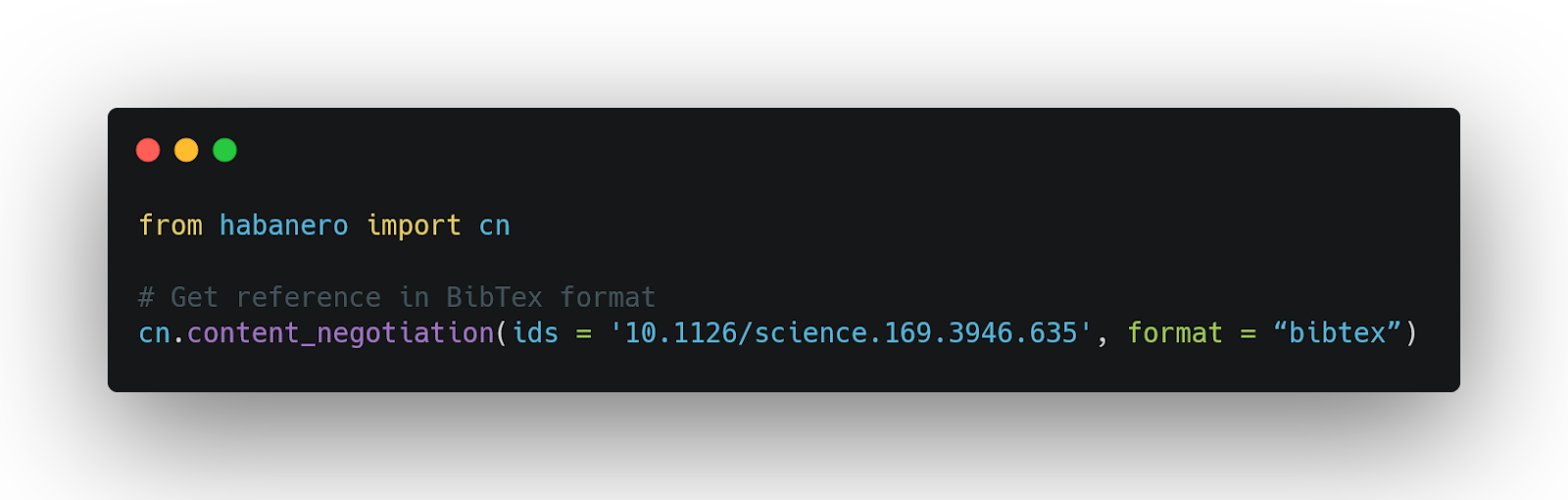
With the DOI in my hands, it was pretty easy to to get the citations in the bibtex format I wanted. I already knew that several web servers providing this service exist, such as doi2bib. I knew it was possible to programmatically do that. What I didn't realize is that I could do it directly with the CrossRef API Habanero!
Moreover, it requires a single command:
Figure 3: Using habanero to retrieve the citation format you like is easy as that. Check out all the possible formats.
So, I could simply iterate over all the DOIs of the papers to get the BibTeX for each one. By the way, CrossRef allows you to get the citation in an insane number of formats (here's a list). If you ever want to explore that, I leave you an interesting page: Content Negotiation.
Step 4: A MathOnco dataset
This project aimed to obtain the references of the papers collected in the MathOnco newsletter in seven years. Having a single .bib file “to rule them all” is pretty cool, but both me and Jeffrey knew that we had in our hands much more than that. We had a slice on 7 years of research papers in our field, giving us an unmissable occasion to analyze the investigations in the field for such a long time. And the way to do that is a bibliometric analysis.
Probably, most of the readers are familiar with bibliometrics. Is the statistical analysis of any kind of publication, including research papers. This field has a great impact on researchers' careers as some of the most popular bibliometric measures (e.g. citations, H-index, etc) are widely used to evaluate the quality of an investigator. And the same techniques can be used to analyze a field of science as Mathematical Oncology.
Being both Jeffrey and I absolute beginners in the field, we called Barbara S. Lancho Barrantes (University of Brighton), who kindly offered her help to conduct a preliminary analysis of the papers we collected. Using Scopus, she could retrieve many interesting facts regarding our dataset. Below, we have collected some "Top 10s" that might interest you.
Rank List of Authors
#
Name (Papers)
1
Anderson, A.R.A. (42)
2
Brown, J.S. (42)
3
Gatenby, R.A. (39)
4
Yankeelov, T.E. (35)
5
Jolly, M.K. (30)
6
Enderling, H. (28)
7
Graham, T.A. (23)
8
Hormuth, D.A. (22)
9
Sottoriva, A. (22)
10
Robertson-Tessi, M. (19)
Rank List of Journals
#
Journal (Papers)
1
Plos Computational Biology (80)
2
Nature Communications (62)
3
Journal Of Theoretical Biology (48)
4
Bulletin Of Mathematical Biology (46)
5
Scientific Reports (40)
6
Cancers (33)
7
Cancer Research (31)
8
CPT Pharmac. & Systems Pharma. (30)
9
PNAS (30)
10
Journal Of Mathematical Biology (22)
Rank List of Institutions
#
Inst. (Papers)
1
Moffitt Cancer Center (183)
2
Harvard Medical School (68)
3
University of Oxford (67)
4
MD Anderson Cancer Center (58)
5
University of Southern California (53)
6
Harvard University (49)
7
The University of Texas at Austin (46)
8
University College London (45)
9
The Institute of Cancer Research (43)
10
Centre National de la Recherche Sci. (41)
Rank List of Countries
#
Country (Papers)
1
United States (824)
2
United Kingdom (286)
3
Germany (121)
4
France (117)
5
Italy (83)
6
Netherlands (70)
7
Switzerland (66)
8
Canada (65)
9
China (62)
10
Spain (60)
Looking at the top 10 journals containing publications in Mathematical Oncology, it is clear how this field is well-spread and recognized in the scientific community. Indeed, the list includes not only journals that are strictly related to mathematical/computational biology. It also contains cancer-related journals (Cancers, Cancer Research) and general-scope journals (PNAS, Nature Comm, Sci Rep). Geographically speaking, our field is present mainly in North America and Europe. However, a closer look at the top institutions shows that Mathematical Oncology is stronger in the US and the UK. If you’re looking for a job in this field, you might have a visit to these countries. Or maybe look at the papers of the top 10 authors cited in the newsletter! Perhaps you could find exciting work you didn’t know about.
In conclusion, with Python and some patience, I could collect (almost) all the papers of the MathOnco Newsletter in a single .bib file of more than 1500 entries. With Jeffrey and Barbara, we analyzed the references finding the most popular authors, journals, institutions and countries that have been published in the Newsletter throughout the years.
If you want to use the .bib file for your documents, you can find it in the repository we prepared here. If you're just curious regarding the code I used, you can also find it in the very same repository. Enjoy MathOnco community!