Learning to Adapt - Personalizing Adaptive Therapy Schedules using Deep Reinforcement Learning
Behind the paper
Mathematical Model-Driven Deep Learning Enables Personalized Adaptive Therapy
Kit Gallagher, Maximilian A.R. Strobl, Derek S. Park, Fabian C. Spoendlin, Robert A. Gatenby, Philip K. Maini, Alexander R.A. Anderson
Read the paperPrior adaptive therapy trials [1] have relied on a 50% "rule-of-thumb" for determining treatment holidays - treatment is applied until the tumor burden decreases by 50%, at which point it is removed until the tumor returns to the initial size. However, this raises further questions:
- Does this threshold maximize the time to progression?
- Is a "one size fits all" approach even appropriate?
- Should the threshold be personalized for each patient, to maximize the benefits of adaptive therapy?
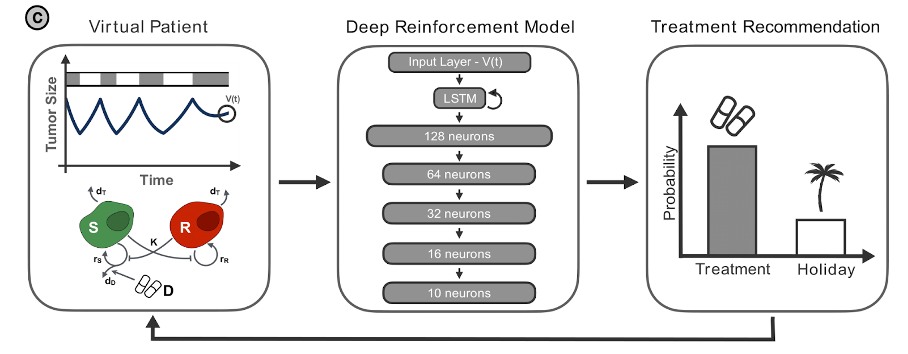
To answer these questions, we applied a deep reinforcement learning (DRL) network to optimize the treatment strategy for a single patient. These ‘deep’ methods use artificial neural networks with many intricately connected layers that enable them to learn highly complex relationships between system variables. DRL frameworks have achieved success in a range of drug scheduling problems, from immune response after transplant surgery [2] to controlling drug resistance in bacteria [3]. At each timestep a deep learning agent is given information on the state of the system (e.g., tumor size), and its output is used to choose from a set of possible actions (e.g., treat vs. not treat). To learn its strategy, the agent is trained through a process of trial and error to maximize a reward function that remunerates success (e.g., tumor shrinkage or cure), and penalizes unfavorable events (e.g., excess drug toxicity). DRL schemes are particularly well suited to this task, as they may account for the long-term effects of actions when maximizing outcomes, even when the relationship between actions and outcomes is not fully known.
To generate the large quantities of data required to train the DRL network, as well as simulate scenarios that would not be feasible to test in the clinic, we use a Lotka–Volterra model calibrated to prostate cancer dynamics [4] to simulate the treatment response of a ‘virtual patient’. Here, we demonstrated that treatment schedules can outperform both the standard of care (continuous therapy) and the current adaptive protocols, more than doubling the time to progression.
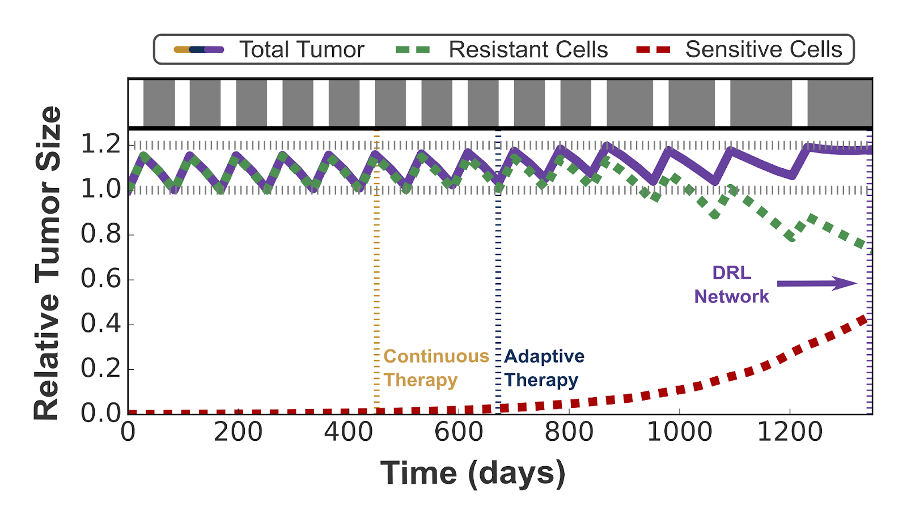
However, the clinical applicability of this is limited by two problems; the `black-box’ nature of the DRL, and the reliance on a patient's complete clinical history to be able to train a DRL network on a virtual patient fitted to their data. We address the first by correlating the input of the network (current tumor size) with its output (the treatment recommendation) and identify a clear and interpretable treatment strategy that could be communicated to a clinician. We find that this strategy is highly sensitive to the patient’s tumor dynamics, motivating the generation of a fine-tuned DRL network for each patient, to personalize the adaptive treatment schedules.
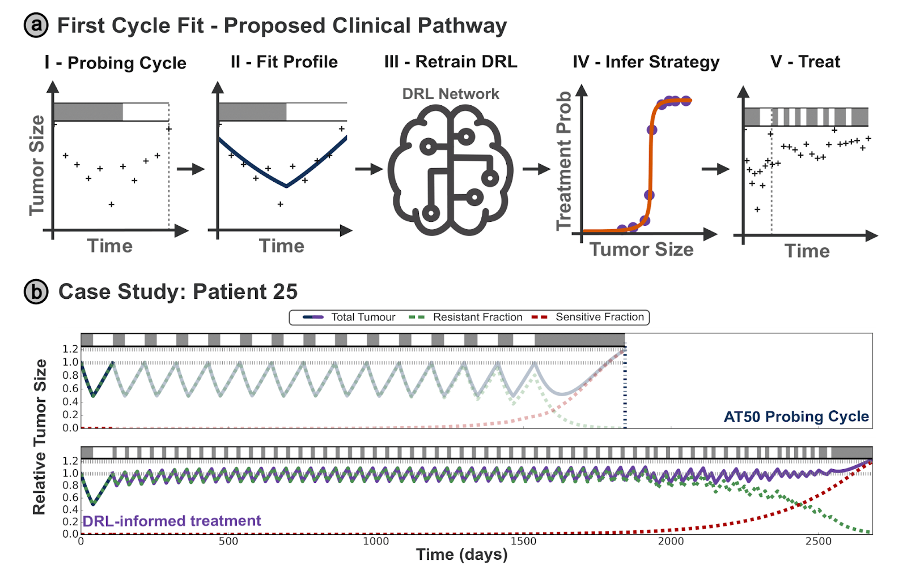
But this highlights the second hurdle - how to fine-tune a treatment strategy for a patient who has just presented in the clinic, with no prior data that can be used to generate a "virtual twin"? We propose that new patients are given an initial cycle of AT50 upon first presentation, during which their tumor burden dynamics are recorded and an estimate of their tumor parameters is inferred. We may then finetune a generic, multi-patient network using this estimated virtual tumor model, to tailor the DRL framework to this patient. Extracting a rational strategy from this network then allows clinical implementation of our DRL-based personalized AT schedule for future treatment cycles.
We find that these schedules consistently outperform clinical standard-of-care protocols as well as generic adaptive therapy, which does not fully account for such inter-patient variation. By tailoring our robust, cohort-trained DRL strategies to individual patients, we have demonstrated a clear route for how the results from our in silico study could be translated to support clinical decision-making.
Full details of this work are now published in Cancer Research [5], and all figures in this post are replicated from that paper.
References
- Zhang J, Cunningham J, Brown J, Gatenby R. Evolution-based mathematical models significantly prolong response to abiraterone in metastatic castrate-resistant prostate cancer and identify strategies to further improve outcomes. eLife. 2022 Jun;11. doi:doi.org/10.7554/elife.76284.
- Liu Y, Logan B, Liu N, Xu Z, Tang J, Wang Y. Deep Reinforcement Learning for Dynamic Treatment Regimes on Medical Registry Data. In: 2017 IEEE International Conference on Healthcare Informatics (ICHI). IEEE; 2017. p. 380-5. doi:10.1109/ichi.2017.45.
- Weaver DT, King ES, Maltas J, Scott JG. Reinforcement learning informs optimal treat- ment strategies to limit antibiotic resistance. Proceedings of the National Academy of Sciences. 2024;121(16):e2303165121. doi:10.1073/pnas.2303165121.
- Strobl MAR, West J, Viossat Y, Damaghi M, Robertson-Tessi M, Brown JS, et al. Turnover Modulates the Need for a Cost of Resistance in Adaptive Therapy. Cancer Research. 2021 Feb;81(4):1135-47. doi:doi.org/10.1158/0008-5472.can-20-0806.
- Gallagher K, Strobl MAR, Park DS, Spoendlin FC, Gatenby RA, Maini PK, Anderson ARA; Mathematical Model-Driven Deep Learning Enables Personalized Adaptive Therapy. Cancer Res 1 June 2024; 84 (11): 1929–1941. doi:10.1158/0008-5472.CAN-23-2040.
© 2026 - The Mathematical Oncology Blog