Data science can help us run better cancer clinical trials
Behind the paper
Cancer patient survival can be parametrized to improve trial precision and reveal time-dependent therapeutic effects
Deborah Plana, Geoffrey Fell, Brian M. Alexander, Adam C. Palmer, Peter K. Sorger
Read the paper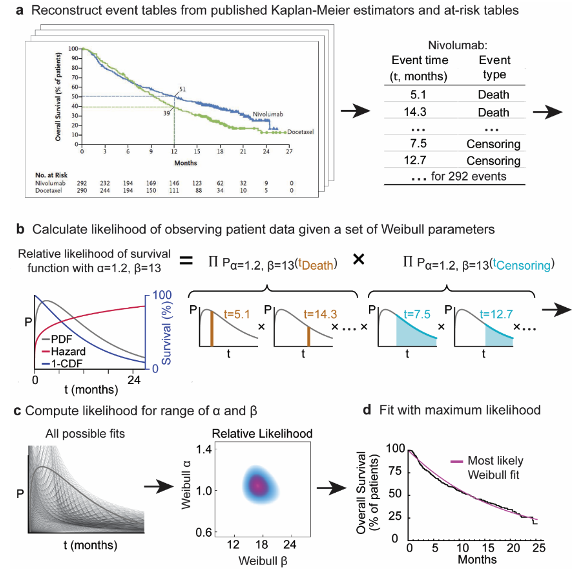
Figure 1: Procedure for parameterizing survival curves starting with published figures. a Kaplan-Meier survival curve and at-risk table obtained from clinical trial publication. Individual participant data were imputed from digitized survival curves and at-risk tables as previously described9. b Each set of parameters corresponds to a different probability density function and survival function (which corresponds to 1 minus the cumulative density function). The likelihood of observing actual data is then computed. c Likelihood calculation is repeated for a set of possible parameter values. d The most likely (best) fit is obtained by finding the parameter values with the maximum likelihood.
Some key insights emerged from analyzing this dataset. First, that a simple two-parameter distribution (the Weibull function) can accurately describe survival data from oncology clinical trials. Second, that by fitting Weibull functions to survival data, parameterized 50-patient trial arms are as accurate and precise in describing drug efficacy (i.e. percent overall survival at 12-months) as 90-patient arms evaluated by traditional non-parametric statistics. This could improve the precision of early-phase trials, obtaining the same signal on a drug’s activity with fewer patients as compared to conventional methods. Third, we show that the length of a trial is related to its likelihood of succeeding, and that this effect is dependent on the shape of the curves in a trial. We hope that these findings highlight the power of re-analyzing published trial results, and inspire others to release de-identified participant events. Patients make an invaluable gift to society by enrolling in clinical trials, and they overwhelmingly support making their data public10. Making the most out of their contribution by releasing and re-analyzing clinical trial results is both a scientific opportunity and an ethical responsibility.References
- Kaplan, E. L. & Meier, P. Nonparametric Estimation from Incomplete Observations. 53, (1958).
- Cox, D. R. Regression Models and Life-Tables. Journal of the Royal Statistical Society. Series B (Methodological) 34, 187–220 (1972).
- Hede, K. Project Data Sphere to Make Cancer Clinical Trial Data Publicly Available. JNCI Journal of the National Cancer Institute 105, 1159–1160 (2013).
- Ross, J. S. et al. Overview and experience of the YODA Project with clinical trial data sharing after 5 years. Sci Data 5, 180268 (2018).
- National Cancer Institute (NCI). National Clinical Trials Network (NCTN) and NCI Community Oncology Research Program (NCORP) Data Archive. https://nctn-data-archive.nci.nih.gov/about-us. (2021).
- Danchev, V., Min, Y., Borghi, J., Baiocchi, M. & Ioannidis, J. P. A. Evaluation of Data Sharing After Implementation of the International Committee of Medical Journal Editors Data Sharing Statement Requirement. JAMA Network Open 4, e2033972 (2021).
- Plana, D., Fell, G., Alexander, B. M., Palmer, A. C. & Sorger, P. K. Cancer patient survival can be parametrized to improve trial precision and reveal time-dependent therapeutic effects. Nat Commun 13, 873 (2022).
- Plana, D., Fell, G., Alexander, B. M., Palmer, A. C. & Sorger, P. K. Imputed individual participant data from oncology clinical trials. https://doi.org/10.7303/SYN25813713 (2021).
- Fell, G. et al. KMDATA: a curated database of reconstructed individual patient-level data from 153 oncology clinical trials. Database 2021, baab037 (2021).
- Mello, M. M., Lieou, V. & Goodman, S. N. Clinical Trial Participants’ Views of the Risks and Benefits of Data Sharing. New England Journal of Medicine 378, 2202–2211 (2018).
© 2026 - The Mathematical Oncology Blog