A holistic comparison of complex model outputs
Behind the Paper
Siamese neural networks for a generalized, quantitative comparison of complex model outputs
Colin G. Cess, Stacey D. Finley
Read the preprint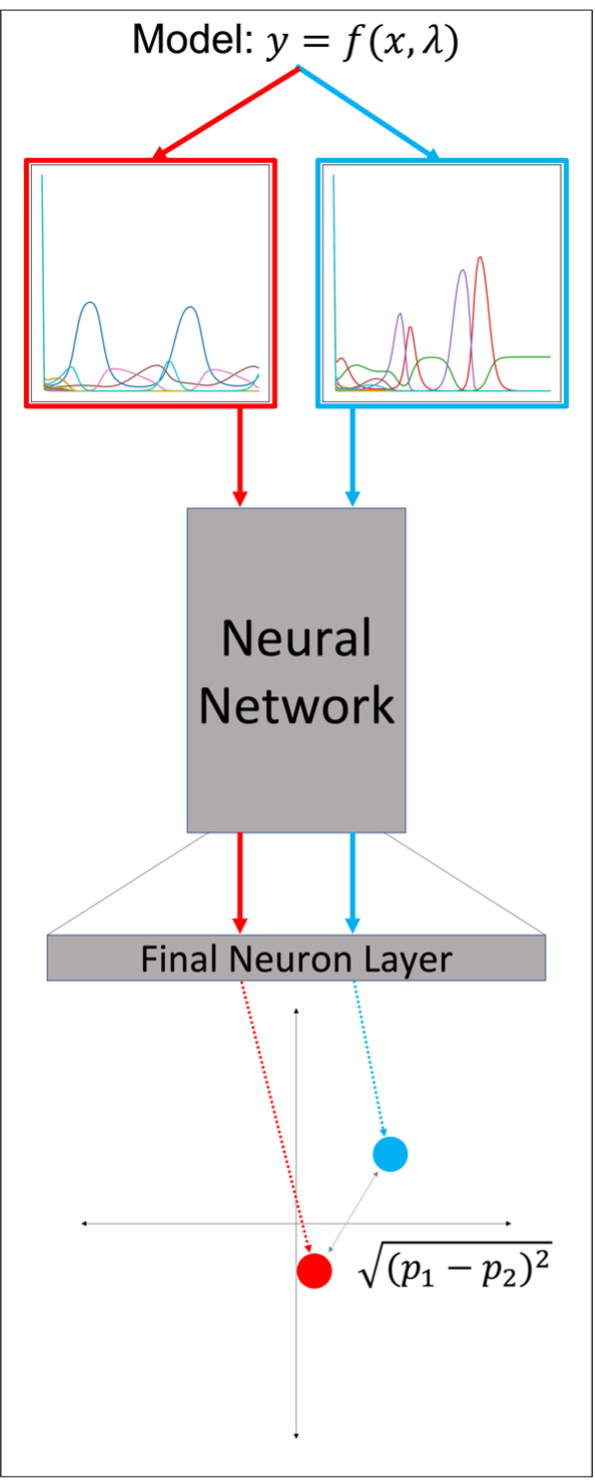
Figure 1: Overview of using a Siamese neural network to project a pair of simulations into low-dimensional space. Taking the distance between projected points provides a metric for determining the similarity between simulations. The smaller the distance, the more similar they are.
The first step of this approach is to produce a training dataset for the Siamese network. We do this by randomly sampling from a uniform distribution for each parameter that we may want to vary, over the widest range that we would want to vary it, producing a set of Monte Carlo simulations. We use this dataset to train the Siamese network via triplet loss5, which compares the distance (D) between projected points for an anchor (A) and positive (P) sample to the distance between A and a negative (N) sample, aiming to minimize D(A,P) and maximize D(A,N). To obtain A, P, and N, we randomly select two simulations to be A and N. P is then generated by adding Gaussian noise to A. Many triplets are randomly formed, which are then used to train the Siamese network. Once we have trained the Siamese network, we can perform a number of different analyses with it. The first example we show is with a four-species Lotka-Volterra model, with the base parameters tuned to create oscillatory behavior6. We perform a sensitivity analysis, comparing the sensitivity ranking obtained when using the distance calculated by a Siamese network to the change in a specified sensitivity output, the traditional way of performing sensitivity analysis (Figure 2). Parameters are then ranked by their sensitivity. We see that there are some discrepancies in the ranked parameters, due to the fact that a specified output only looks at a small region of output space, while the Siamese network accounts for the entire output.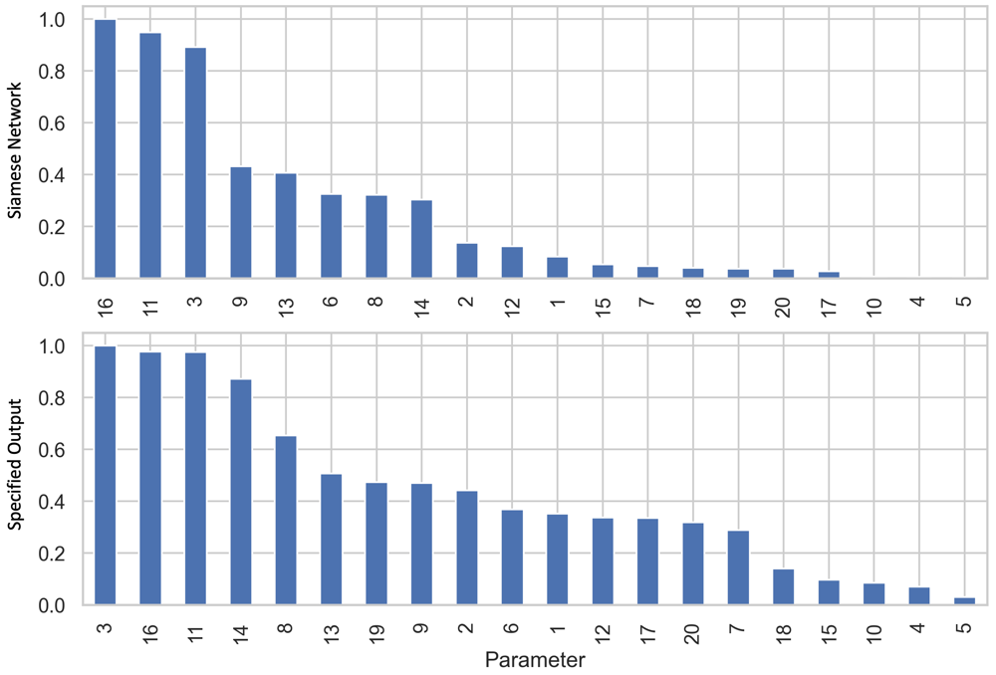
Figure 2: Comparison of using a Siamese network to using a specified output for a sensitivity analysis. Sensitivities are normalized to the highest value. We see that while some parameters are ranked similarly, other parameters are ranked very differently. This is due to the differences in how the sensitivity output is measured.
Lastly, we show an example of applying our approach to an agent-based model of tumor-immune interactions7. These models are stochastic and produce complex spatial outputs. Here, we examine the final spatial layout of the simulation. Rather than just calculating the distance between two simulations, we instead use the Siamese network to project the Monte Carlo simulations into low-dimensional space, allowing us to easily cluster the simulations (Figure 3). From this, we can then examine the distributions of the parameters for each cluster, drawing insight on how different tumor properties can yield different end-states. Additionally, we can examine the distributions for specific model outputs, giving us further insight beyond the low-dimensional projections performed by the Siamese network.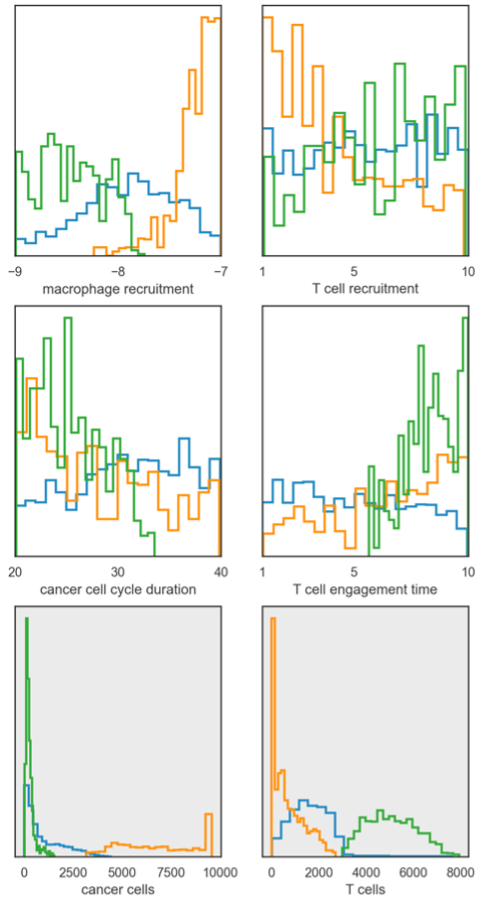
Figure 3: Distributions for parameter values (top two rows) and specific outputs (bottom row) for clustered model simulations.
Our approach facilitates a holistic comparison of model simulations, accounting for the complex relationships between outputs without having to specify a comparison metric. This is similar to the work by Tapinos and Mendes8, with the distinction that our method is not limited to model outputs in the form of time-series. Our approach can be used on disparate model types and applied in various different types of analyses. We hope that this approach provides researchers with another way to explore their models in further detail.References
- Campbell, K., McKay, M. D. & Williams, B. J. Sensitivity analysis when model outputs are functions. Reliability Engineering & System Safety 91, 1468–1472 (2006).
- Lenhart, T., Eckhardt, K., Fohrer, N. & Frede, H.-G. Comparison of two different approaches of sensitivity analysis. Physics and Chemistry of the Earth, Parts A/B/C 27, 645–654 (2002).
- Li, D. & Finley, S. D. Mechanistic insights into the heterogeneous response to anti-VEGF treatment in tumors. Computational and Systems Oncology 1, e1013 (2021).
- Chicco, D. Siamese neural networks: An overview. Artificial Neural Networks 73–94 (2021).
- Hoffer, E. & Ailon, N. Deep metric learning using triplet network. in International workshop on similarity-based pattern recognition 84–92 (Springer, 2015).
- Vano, J., Wildenberg, J., Anderson, M., Noel, J. & Sprott, J. Chaos in low-dimensional Lotka–Volterra models of competition. Nonlinearity 19, 2391 (2006)
- Cess, C. G. & Finley, S. D. Multi-scale modeling of macrophage—T cell interactions within the tumor microenvironment. PLoS Computational Biology 16, e1008519 (2020)
- Tapinos, A. & Mendes, P. A method for comparing multivariate time series with different dimensions. PLoS ONE 8(2): e54201 (2013).
© 2026 - The Mathematical Oncology Blog